Spark SQL & Pyspark: A Guide To Creating Tables
Can mastering data manipulation transform the way we interact with information? The ability to craft and manage data tables, a fundamental skill in today's data-driven world, holds the key to unlocking insights and driving informed decision-making.
The "CREATE TABLE" statement is the cornerstone of defining structures within existing databases, serving as the initial step in organizing and storing data. The "CREATE TABLE" statement, in its various forms, provides the framework upon which all data operations are built. Whether using Hive format or leveraging Spark SQL, the goal remains the same: to establish a structured repository for data, ready to be queried and analyzed.
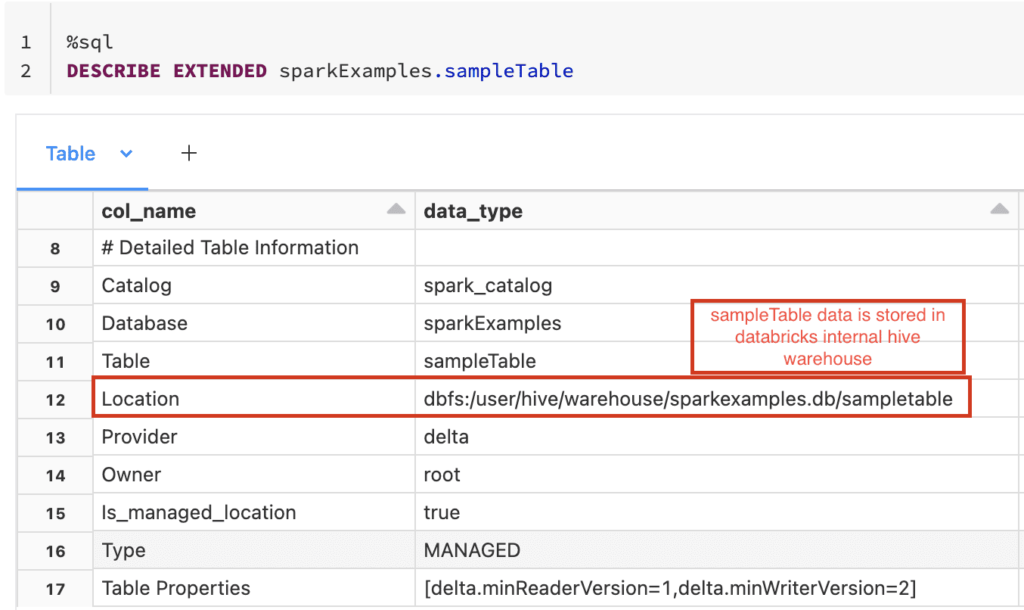
The creation of tables through Spark SQL offers a dynamic approach, enabling the generation of tables directly from dataframes. The `saveAsTable()` method, available within the `DataFrameWriter`, facilitates the creation of Hive tables from both Spark and PySpark dataframes, offering a versatile means of persisting data. Dataframes themselves become indispensable, representing the structured data that will populate these tables. An external table is created when a path is specified, sourcing its data from a location specified. Otherwise, a managed table is generated. The data source of this table, indicated with specifications like 'parquet' or 'orc', ensures data is properly formatted. If no source is specified, the system defaults to the one configured by `spark.sql.sources.default`.
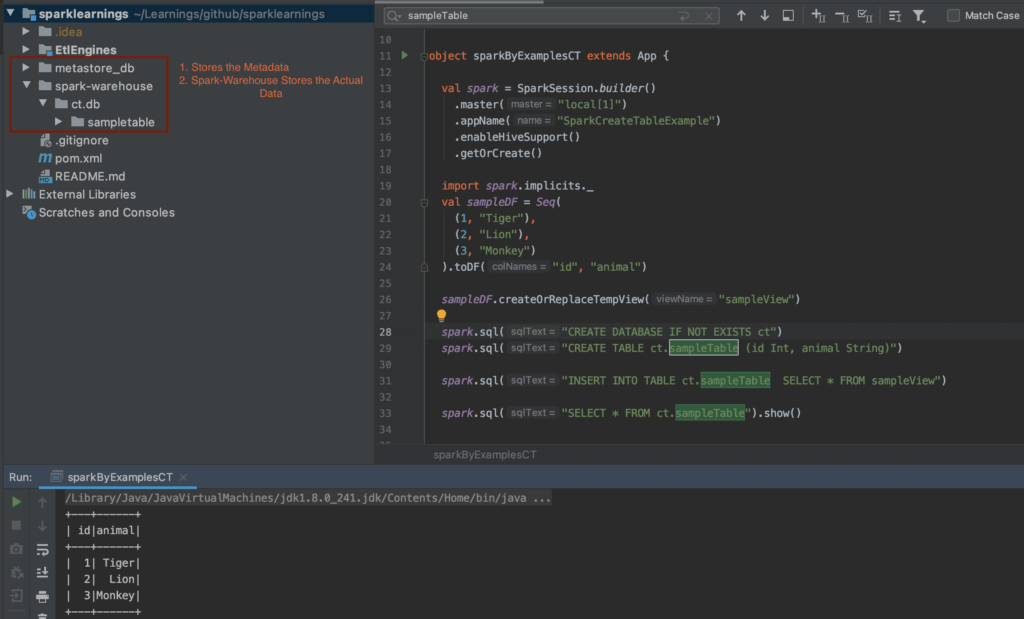
Dropping a table before creating a new one is frequently necessary. The command `Spark.sql(drop table if exists + my_temp_table)` offers a straightforward method for removing any pre-existing temporary tables. Following the dropping of a table, we create the table. For example, `Spark.sql(create table mytable as select from my_temp_table)` creates a table named `mytable` in the appropriate storage location. The scope of temporary tables is restricted to the session in which they are created, while permanent tables, created in a database, have a broader scope. Creating tables, especially temporary ones, often involves the use of temporary views, such as those created via `createorreplacetempview`, which generate tables within the `global_temp` database. A more appropriate strategy involves a modification, like `Create table mytable as select from global_temp.my_temp_table`, to explicitly designate the temporary table's namespace.
The method for creating a table in a new database after switching to the new database is straightforward. The statement `Spark.sql(create table if not exists mytable (id int, name string))` is a core component to creating a table. This would create a table named `mytable` with columns `id` and `name` as examples. Using `spark.sql(drop table if exists + my_temp_table)` to drop the table is common, as is `spark.sql(create table mytable as select from my_temp_table)` to create the table. `createorreplacetempview` helps to create tables in the global_temp database. A more common approach would be to `create table mytable as select from global_temp.my_temp_table`.
The data source is dictated by the specified source and associated options. When no source is explicitly defined, the default data source configured by `spark.sql.sources.default` is employed. When a path is provided, an external table is formed from the data located at the designated path. If no path is specified, a managed table is created. Data from existing tables can be queried using `df_fact_sale = spark.read.table(wwilakehouse.fact_sale)`, followed by similar commands for `df_dimension_date` and `df_dimension_city`, allowing for the joining of these tables using the dataframes. Further refinement can be made via grouping and renaming.
Iceberg tables, offering advanced features for data management, can be initiated with a "CREATE TABLE" command. The command `demo.nyc.taxis` would create a table, using demo for the catalog, nyc for the database and taxis for the table. Interacting with iceberg tables relies on SQL and the DataFrames API. The processes for creating and adding data to these tables utilizes both Spark SQL and Spark DataFrames. For auto-partition discovery, using the command like create table my_table using com.databricks.spark.avro options (path /path/to/table); can be achieved.
Using `sparkSession` enables access to PySpark SQL capabilities within Apache PySpark. Once a temporary view is in place, standard ANSI SQL queries are executable using the `spark.sql()` method. For example: `# run sql query spark.sql(select firstname, lastname from person).show()` results in the output. `createorreplacetempview()` is used on Azure Databricks. A storage format for Hive tables must be specified, defining how the table reads and writes data, through the use of an "input format" and an "output format". Tasks include creating an empty table using either `spark.catalog.createtable` or `spark.catalog.createexternaltable`. The creation of a database and an accompanying table, such as `{username}_hr_db` and the `employees` table, are common practices. Parquet file format is used when creating tables, as in the `order_items` table. Snappy algorithm is used for compressing the files using Parquet format. Spark context is started to execute the code provided. The `CREATE TABLE` statement in Spark SQL resembles standard SQL, but it utilizes Spark's unique features and syntax. Here's the basic syntax for creating tables in Spark SQL.
The command `create table (hive format)` applies to: This statement matches create table [using] using hive syntax. Create table [using] is preferred. Using this syntax, one can create a new table, based on the definition but not the data, of another table. Lakehouse tables, acting as bronze layers, are the destination for pipelines from source CSV files. These tables also serve as the foundation for views within the data warehouse. (create view warehouse.dbo.testview as select from lakehouse.dbo.testtable.)
One can create a "pointer" and ensure it points to the existing resources. From `pyspark.sql import sparksession` to create the session. It's possible to create a table on Spark by means of a select statement. The fundamental differences between internal and external tables in Hive are important. The standard syntax for table creation in an existing database is through a "CREATE TABLE" statement. Create table using hive format. Tables can also be created as delta lake tables using a pure SQL command: `spark.sql( create table table2 (country string, continent string) using delta )`. Once a temporary view is registered, SQL queries are run using the `spark.sql()` method. The results are processed, and further manipulated as needed.
Create a temporary view or table in pyspark by registering a dataframe as a temporary view. Run an arbitrary SQL query using `spark.sql()`. This uses the apache spark `spark.sql()` function to query a SQL table using SQL syntax.
| Aspect | Details |
|---|---|
| Core Concept | Creating and managing tables in data processing frameworks like Spark SQL is a fundamental task for organizing and analyzing data. This involves defining table structures, specifying data sources, and managing data persistence. |
| Key Technologies | Spark SQL, DataFrames, Hive format, Delta Lake, Parquet, ORC, Apache Spark, PySpark. |
| Key Commands/Methods | CREATE TABLE, saveAsTable(), drop table if exists, createorreplacetempview(), spark.sql(), spark.read.table(), create table as select |
| Types of Tables | Managed tables (internal), External tables, Temporary tables, Iceberg tables, Delta Lake tables. |
| Data Sources | Parquet, ORC, CSV, JDBC, and others. The default data source is configured by spark.sql.sources.default. |
| Table Management | Includes creating, dropping, and querying tables. The use of temporary views and permanent tables impacts the scope and persistence of the data. |
| Benefits | Organizing data for efficient querying, enabling complex data transformations, integrating with various storage formats, and preparing data for analysis. |
| Syntax | The SQL commands can be standard, and spark-specific. Examples: CREATE TABLE mytable (id INT, name STRING), CREATE TABLE table2 (country STRING, continent STRING) USING delta |
| Key considerations | Data Source, Table Type (Managed vs. External), Data Compression, Storage Formats (Parquet, ORC). |
| Example Usage | `CREATE TABLE employees (id INT, name STRING, department STRING) USING parquet` |
| Resources | Apache Spark Documentation on Hive Support |
One of the key facets of table creation is choosing the correct approach based on the circumstances. Managed tables, for instance, store both the data and metadata and are best suited for scenarios where Spark has full control over the data's lifecycle. External tables, on the other hand, link to data stored externally, letting you manage the data's location and structure outside of Spark. A table is generally created by using the CREATE TABLE command and includes table name, along with the data definition language. Table is created based on the existing data source.
Spark SQL allows you to define a table and specify various parameters in the table definition. It is also possible to use `create table mytable as select from global_temp.my_temp_table`. The create table statement is used to define a table in an existing database, and there are various formats possible. In the context of Azure Databricks, `createorreplacetempview()` is often used to make temporary views available. Another factor to consider is how your data is organized in storage and selecting the best file format. This could be done with Parquet or ORC. The system default is set using `spark.sql.sources.default`. For hive table, one must define how to read/write the data from/to the file system, i.e., the input format and output format. If an external table is being created, a path is provided. If a managed table is being created, no path is needed.
The flexibility in specifying the data source with its accompanying options, such as the file format (e.g., Parquet, ORC) and compression algorithms, further increases the control. The method `spark.sql(create table if not exists mytable (id int, name string))` is useful for creating tables with specific columns, and the type of columns are also specified. When tables are created using Parquet files, the data is often compressed using algorithms such as Snappy. In addition, you can create a table by using the command `create table mytable as select * from my_temp_table`. The temporary views can also be created using the command like `createorreplacetempview`. The DataFrames API and SQL are often used together. The creation and the management of the data is done with SQL syntax.


{kind=link}